November 20, 2019
The Disruptions of Neural Machine Translation
Introduction
According to the Future of Humanity Institute in Oxford, an estimate recently widely relayed by the World Economic Forum, machine translation should outperform human translation by 2024… and so translation and more generally the language services industry stand to be among the first to be disrupted by AI technologies.1Cp. Charlotte Edmond, “This is when a robot is going to take your job, according to Oxford University”, posted July 19, 2017 on www.weforum.org. Available at https://www.weforum.org/agenda/2017/07/how-long-before-a-robot-takes-your-job-here-s-when-ai-experts-think-it-will-happen/ [accessed January 5, 2019]. The recent launch of free online neural machine translation tools, such as DeepL or Google Translate’s new version, are bound to disrupt the translation market due to their worldwide availability and enhanced performance. These tools are already easily accessible either on the net or via apps, and the next step for the industry is to embed them in many smart appliances like digital assistants or cars.2For instance, the Google translate app for phones has been widely used by football fans in Russia during the 2018 World (Smith 2018) and a consortium of Japanese firms has developed Voice Tra, a free translating app targeting fans and tourists for the 2020 Summer Olympics. This obfuscates the whole production and mediation process, masking the materiality of translation. Yet this very process, the medium of production is essential, especially when dealing with such a core social and political activity as language. In his study of digital economy, Olivier Bomsel pointed out that the medium acts both as a materialization of the symbols it transmits, a tool to organize meaning, a tool to enact physical distribution and an exclusion tool upon which the definition of property and the attending rules rely.3Cp. Olivier Bomsel, L’Economie immatérielle, Paris, Gallimard, 2010, pp. 123-124 (my translation). One might add that the medium also acts as an identification tool (specifying the source, the author of the text) and as a venue for the conquest and assertion of power. As the materiality of translation disappears from view (and public debate), it becomes urgent to investigate the making of neural machine translation (NMT), to identify the genealogy and specificity of translation tools, to uncover the current sociology and geography of NMT agents, and to examine its impact on our relation to language.
A Short History of Translation and its Imaginaries

To understand the disruptive force of neural machine translation, it is useful to retrace its genealogy within the history of translation. Translation, because it is a complex linguistic operation, was seen as a quintessentially human activity. It was usually represented by the figure of St. Jerome, an elderly scholar surrounded by books, to which one may add the team of 72 translators who translated the Torah from Hebrew to Greek, around 270 BC (see figure 1).
These representations showcased two important dimensions of the work: the length of time needed to translate (as indicated by Jerome’s age) and the debates and discussions inherent to the process of translation (as indicated by the great number of books or contributors). Since the advent of computers and digital text processing, scientists have tried to devise automated machine translation tools. The first stage of machine translation at an industrial level,4There are numerous accounts of the history of machine translation. The following is both precise and accessible to non-specialists: Ilya Pestov, “A History of Machine Translation from the Cold War to Deep Learning”. Available at https://medium.freecodecamp.org/a-history-of-machine-translation-from-the-cold-war-to-deep-learning-f1d335ce8b5 [accessed August 20, 2018]. starting in the late 60s and 70s, was based on linguistic rules, mostly lexical and morphological analysis coupled with the use of dictionaries. Its logic corresponded to that of the grammar book, a formal description aiming at some a posteriori rationalization of language. Rule-based machine translation processing was lengthy and error-ridden because it could not take into account the ambiguities and quirks of real-life language. Then toward the end of the 80s, researchers, notably from IBM and the German branch of Systran, developed statistical machine translation (SMT). This time the focus was on the production of native speakers, collected and ordained into huge databases. The whole process was based on matching databases of textual segments from different languages, without taking into consideration meaning and context. This shift to a mathematical approach in translation, embodied by the quest for the “perfect match”, may be argued to correspond to a larger trend within humanities, as identified by N. Katherine Hayles:
“The emphasis on databases in Digital Humanities projects shifts the emphasis from argumentation – a rhetorical form which historically has foregrounded context, crafted prose, logical relationships, and audience response – to data elements embedded in forms in which the structure and parameters embody significant implications.”5N. Katherine Hayles, How We Think: Digital Media and Contemporary Technogenesis, Chicago, Chicago University Press, 2012, p. 39.
But texts translated via SMT still contained many errors and seemed unnatural, again because the technology could not deal with homonyms and context. Then in a third phase, researchers integrated artificial intelligence technologies in the process, introducing machine learning to improve statistical machine translation by using predictive models. The reference to neurons, the very fact the algorithm gradually improves its performance via trial and error and the fluency of translations, all suggest the machine can work like a human brain, thereby legitimizing it and seemingly repatriating it within human-like activity. This obfuscates the mathematical nature of the process, its reliance on databases and computing power and its radical departure from natural language (NMT is based on the encoding and decoding of text into layers of semantic vectors that do not correspond to an existing natural language). One should add that the interfaces of DeepL and Google Translate are designed to give an immediate access to the translation result, simplifying the user experience into a mere sequence of copy/paste/click. In a sense those translation interfaces could be described as a form of artifice, theatrical tricks that overshadow the cumbersome process of translation. One could compare the artifice of neural machine translation to Marcello Vitali Rosati’s analysis of cloud computing:
“a metaphor that suggests that our data are immaterial, that they are nowhere, that they are light, and thus that they do not cost anything, that they are not on a particular hard-disk of a specific computer in a specific place, owned by a specific company. The ‘cloud’ metaphor as such is a way of forgetting all the economical, geopolitical, and social implications of a particular material infrastructure.”6Marcello Vitali-Rosati, On Editorialization, Space and Authority in the Digital Age, Amsterdam, Institute of Network Cultures, 2018, p. 23.
In this perspective, it could be fruitful to read the notion of artificial intelligence through the opposition between open and opaque processes of production, rather than the human versus machine paradigm. If one wants to understand the political and social implications of free ubiquitous machine translation, it is essential to investigate the hidden (infra-)structures, interactions and actors of neural machine translation, the “set of dynamics that produce and structure [this specific] digital space”7This is an excerpt from Vitali-Rosati’s definition of editorialization: “Editorialization is the set of dynamics that produce and structure digital space. These dynamics can be understood as the interactions of individual and collective actions within a particular digital environment.” (ibid., p. 7).
How and Where is Neural Machine Translation Produced?
On Google Scholar, I have conducted a systematic survey of research articles on “neural machine translation” published in 2017 and written in the English language. The request yielded 2,900 articles over a total of roughly 4,800 articles on this topic: approximately 60 % of the output on Google Scholar was thus published in 2017. Although Google Scholar does not index all research articles, its collecting policy covers both individual researchers’ websites, university repositories and journals.8Cp. Google Scholar, “Inclusion Guidelines for Webmasters”. Available at: https://scholar.google.com/intl/fr/scholar/inclusion.html [accessed January 5, 2019]. It also boosts the readership and visibility of those articles. Provided the sample is large enough, it can therefore constitute a representative source of current trends in research. I then focused on the 50 articles ranked as most relevant by the Google Scholar algorithm. One striking feature of the sample was the glaring absence of linguists or humanities scholars: these research articles are written almost exclusively by researchers from Schools of Computing and Engineering, or Departments for Computer Science.9When not Computing Science, the most common heading for those research centres would be Language Technologies, for instance at Carnegie Mellon or Dublin City University, but they are clearly labelled as computational linguistics and deliver MSCs, not MAs. It entails a momentous shift of perspective on translation, moving from a focus on language as it is practiced daily and usually translated to content tailored to be processed swiftly by algorithms.10Artificial Intelligence technologies thus contribute to widen the gap between Translation Studies and Computational Linguistics that has been noted by Frank Austermühl, “On Clouds and Crowds – Current Developments in Translation Technology”, T2IN Translation in Transition, 2011, pp. 1-25 and Miguel Jimenez-Crespo, Translation and Web Localization, Abingdon, Routledge, 2013, pp. 88-90. Checking the institutional origin of those articles revealed a heavily polarized geography. On the one hand 46 % of the articles in the sample were written in English speaking countries, half in the USA (24 %) and half in other countries, mostly Ireland and the UK. On the other hand, 30 % were written in Asia, mostly China and Japan, with one coming from South Korea. Europe came third with 12 %, mostly from Germany and Poland. Closer examination of the data reveals another factor, the weight of corporate research. 40 % of the articles in the sample were authored by researchers privately employed by such online tech giants as Google Brain, Facebook AI, Amazon or Microsoft, including Asian companies like Huawei Technologies, Tencent or Samsung Electronics, to which one should add a number of articles authored by academics but funded by those same corporations (ten articles, one fifth of the sample). The polarization of NMT research between the USA and China, as reflected in Google Scholar, appears to reflect the polarized landscape of the tech industry, a finding consistent with the current American/Chinese contest for digital supremacy.11Cp. Unknown Author, “FAANGS v BATS: the world’s tech giants are competing in new markets and the stakes are high”, The Economist, July 7, 2018, pp. 10-11. Cp. also “A wall of money. Quite suddenly the tech firms have become the world’s biggest investors.”, Schumpeter column, The Economist, July 7, 2018, p. 52. This would also account for the relatively small number of language pairs under study: English is the one systematically recurring component, paired out either with Chinese or Japanese, or with a few European languages (German, Czech, Russian, Spanish, French). Such lack of linguistic diversity can be explained by data availability since neural machine translation requires training on large pre-existing corpuses of aligned segments, which are scarce or proprietary. It reinforces the hypercentrality of the English language12Cp. Gisele Sapiro, “Center and periphery: Asymmetrical Flows of Translation”, in Sandra Bermann and Catherine Porter (eds.), A Companion to Translation Studies, Chichester, Blackwell Wiley, 2014, pp. 82-94. to an unprecedented level, and leaves out languages such as Portuguese or Arabic spoken by hundreds of millions of users.13Google Translate boasts it can translate over 100 languages, including Portuguese and Arabic but not as efficiently for all language pairs. DeepL focuses to this day on seven Western languages: French, English, German, Italian, Spanish, Dutch, Polish.
The survey also revealed translation was seen as part of a wider attempt to improve the processing of multimodal content, especially when matching text, image and voice14Within the sample, see Iacer Calixto, Qun Liu and Nick Campbell, “Incorporating Global Visual Features into Attention Based Neural Machine Translation”, Computer Science – Computation and Language, I.2.7, 2017. Available at: https://arxiv.org/pdf/1701.06521.pdf [accessed January 5, 2019] or the work of Elliot et al., funded by French and Dutch public institutions and Amazon Academic Research. Available at: https://arxiv.org/pdf/1710.07177.pdf [accessed January 5, 2019]. For text-to-speech … Continue reading for the purpose of improving the performance of digital assistants likes Alexa, voice-activated devices or cross-media tagging on social media. Google Translate has clearly been updated for phone users, enabling finger writing or the translation of text embedded in pictures.
The sample under study has shown a profound disruption of the sociology and geography of translation. The polarization of research on NMT between the USA and China is cause for concern since those two countries have a history of extensive surveillance, censorship or fake news distribution, both through state bodies and private companies. This concern is bound to be amplified by the ubiquitousness of AI powered translation, freely available online and embedded as APIs in many appliances, websites and social media.
Economic, Political and Philosophical Issues
The most glaring consequence of such disruption of the translation market is the increased power of a handful of tech corporations. Because neural machine translation requires powerful IT capacities and huge training corpuses,15Cp. Kirti Vashee, “Understanding the economics of machine translation”, Translation Spaces, 2 (1), p. 139. DOI: https://doi.org/10.1075/ts.2.07vas [accessed August 20, 2018]. one can expect a further concentration of its major providers, leading to an oligopoly of global language service providers such as Systran, Star or Omniscien, together with the main tech giants such as Google, Amazon, Weibo etc. In this rarefied landscape, issues of reliability, accountability and privacy are bound to surface. One can cite the recent leakage scandal in Norway: Lise Randeberg revealed to the press in September 2017 she had found via Google search “notices of dismissal, plans of workforce reductions and outsourcing, passwords, code information and contracts” that had been fed by various companies to Translate.com and stored on the cloud.16Florian Faes, “Translate.com exposes highly sensitive information in massive privacy breach”, posted September 7, 2019 on slator. Available at: https://slator.com/technology/translate-com-exposes-highly-sensitive-information-massive-privacy-breach/ [accessed August 20, 2018]. Information leakage is just the tip of the iceberg here. If one reads their terms and conditions,17Cp. Google, “Privacy and Terms”. Available at: https://policies.google.com/terms#toc-content [accessed August 20, 2018]. all content fed into free translating tools belongs to the corporations operating them. This raises issues of copyright in some cases and constitutes another intrusive foray into our private lives, for the data thus collected will serve to refine profiling, marketing and surveillance. NMT stands thus as another addition to digital monitoring technologies, widening up their already considerable grasp on our interactions.
Finally, neural machine translation, together with other AI-based language processing tools, may impact our relation to language. From a technical point of view, there is a shift from natural languages, inherently messy and constantly evolving, to streamlined linguistic content and data produced for machine processing, corresponding to a form of “controlled language”.18Miguel Jimenez-Crespo, Translation and Web Localization, London and New York, Routledge, 2013, p. 199. From a user point of view, the diversity and complexity of translation is reduced to a single transfer operation. DeepL’s interface for instance automatically detects the language of the user via the IP address or settings of his device, defines the standard length of a message as 5,000 signs and through the pairing up of two identical windows, strongly suggests there is only one translation for one source text when natural languages allow for a plurality of translated versions.
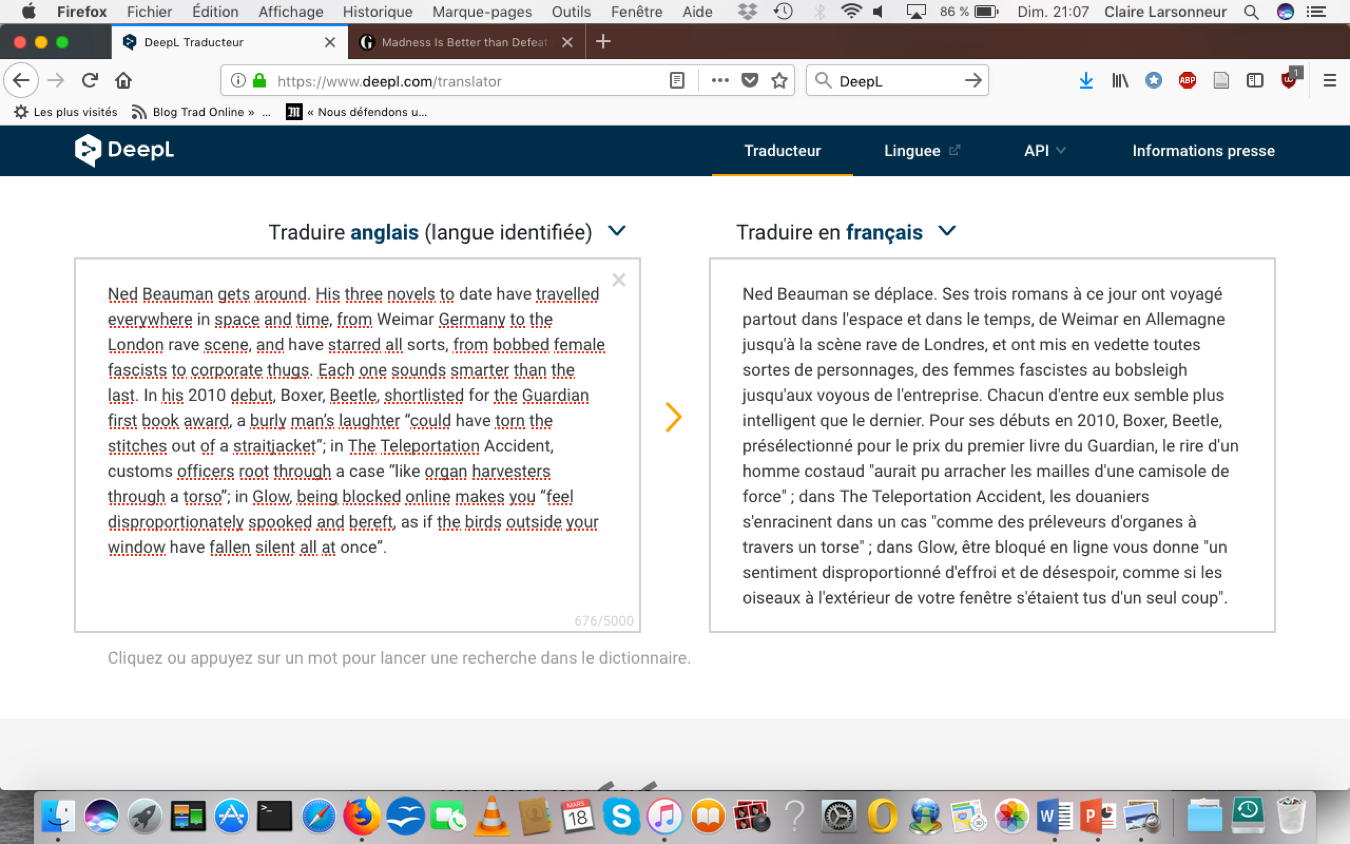
In the case of free translation tools, not only do “devices, digital platforms, tools, networks, and protocols simultaneously provide the context of the content and act as the elements that structure this content”19Vitali-Rosati, 2018, p. 68., they create the content. Indeed, from the point of view of communication theory, rather than messages being transmitted from human to human via a variety of media, we are now facing a situation where messages can originate either from machines or humans and be intended either for humans or machines (such as indexing robots or virtual assistants). In other words, the media becomes both sender and receiver. When an increasingly greater proportion of the texts and messages we are exposed to, both online or via smart appliances, are produced by machines, one may expect an increased standardization of languages. For instance, the more we rely on translation apps when abroad, as Dr. Joss Moorkens suggests, “the more we might be ‘trained’ by those apps to speak in such a way to ensure the most accurate translation. ‘People will probably end up trained to speak in a restricted or unnatural way in order to achieve the best result’, he said.”20Rory Smith, “The Google Translate World Cup”, New York Times, July 13, 2018. Available at https://www.nytimes.com/2018/07/13/sports/world-cup/google-translate-app.html [accessed August 20, 2018]. Another indication of this momentous shift is that it affects Google itself: Google Senior Webmaster Trends Analyst John Mueller admitted in September Google could possibly be fooled by machine translated content when it comes to ranking search results.21A discussion of how machine-produced content is been used and valued by search engines is to be found in Gino Dino, “Google admits its Neural Machine Translation can fool its search algorithm”, posted September 18, 2018 on Slator. Available at https://slator.com/technology/google-admits-neural-machine-translation-can-fool-its-search-algorithm/ [accessed November 4, 2018].
Lack of diversity, standardization and control of language are iterative processes, so this trend may become massive. Finally, from a wider perspective, AI powered language production raises the issue of authority, not in terms of copyright but as the gateway to meaning. Vitali-Rosati reminds us that “authority does not guarantee that content – whether a sentence, an image, a video, web page, or any other fragment of information – corresponds to reality: authority is what creates reality.”22Vitali-Rosati, 2018, p. 83.
Conclusion
AI powered NMT is a two-faced tool: free ubiquitous quality translation may give an unprecedented boost to exchanges and prove extremely useful to many. But it entails a curtailing of the diversity of languages and bypasses the element of debate and interpretation that was inherent to translation and that constituted its contribution to collective thought. The streamlining and standardization of language, the oligopolistic nature of the market, the lack of external control and accountability of those actors constitute threats not only to our privacy but also more generally to intellectual life. It might help to widen our perspective on translation beyond the act of moving from source to target and envision translation as a knowledge-sharing ecosystem, as Vitali-Rosati suggests. Online machine-led translation is not just about speeding up transactions between translators and clients. It involves a greater variety of users, from the end client to the teams designing and operating translation tools and all the anonymous online readers and sharers. It shifts economic activity to a handful of tech giants as providers of translation. And it points out to the current absence of national and international policy makers in the field of translation. Copyright law is evolving, albeit slowly,23See for instance the comparative approach of James Meese, Authors, Users and Pirates. Copyright Law and Subjectivity, Harvard, MIT Press, 2018. and privacy rights have been extensively debated but very little so far has been published on the consequences of the language industry’s standards of quality and transparency on our modes of meaning-making. Redefining knowledge as a form of commons, in the wake of Charlotte Hess and Elinor Ostrom’s work,24Cp. Charlotte Hess and Elinor Ostrom (ed.), Understanding Knowledge as a Commons: from Theory to Practice, Harvard, MIT Press, 2007. may enable us to highlight the interactions of its three human and non-human components: facilities, artifacts, and ideas.25Cp. Charlotte Hess and Elinor Ostrom, “Ideas, Artifacts, and Facilities: Information as a Common-Pool Resource”, Law and Contemporary Problems, 66 (1/2), 2003. NMT tools such as DeepL affect both the facilities of knowledge (storing information and making it available) and its artifacts, that is discreet, nameable representations of ideas, in this case by channeling translations. They also trigger issues of digital property rights listed as “access, contribution, extraction, detraction, management/participation, exclusion, and alienation”26Hess and Ostrom, 2007.. The sustainability and accountability of translation processes may not be guaranteed by an oligopolistic and opaque market and it could therefore be precious to redefine translation as a public utility, enabling us to engage with all of its dimensions and implications.27Vanessa Enriquez-Raido, “Translators as adaptive experts in a flat world: From Globalization 1.0 to Globalization 4.0?”, IJOC: International Journal of Translation, 10, 2016, pp. 970-988.
| ↑1 | Cp. Charlotte Edmond, “This is when a robot is going to take your job, according to Oxford University”, posted July 19, 2017 on www.weforum.org. Available at https://www.weforum.org/agenda/2017/07/how-long-before-a-robot-takes-your-job-here-s-when-ai-experts-think-it-will-happen/ [accessed January 5, 2019]. |
|---|---|
| ↑2 | For instance, the Google translate app for phones has been widely used by football fans in Russia during the 2018 World (Smith 2018) and a consortium of Japanese firms has developed Voice Tra, a free translating app targeting fans and tourists for the 2020 Summer Olympics. |
| ↑3 | Cp. Olivier Bomsel, L’Economie immatérielle, Paris, Gallimard, 2010, pp. 123-124 (my translation). |
| ↑4 | There are numerous accounts of the history of machine translation. The following is both precise and accessible to non-specialists: Ilya Pestov, “A History of Machine Translation from the Cold War to Deep Learning”. Available at https://medium.freecodecamp.org/a-history-of-machine-translation-from-the-cold-war-to-deep-learning-f1d335ce8b5 [accessed August 20, 2018]. |
| ↑5 | N. Katherine Hayles, How We Think: Digital Media and Contemporary Technogenesis, Chicago, Chicago University Press, 2012, p. 39. |
| ↑6 | Marcello Vitali-Rosati, On Editorialization, Space and Authority in the Digital Age, Amsterdam, Institute of Network Cultures, 2018, p. 23. |
| ↑7 | This is an excerpt from Vitali-Rosati’s definition of editorialization: “Editorialization is the set of dynamics that produce and structure digital space. These dynamics can be understood as the interactions of individual and collective actions within a particular digital environment.” (ibid., p. 7) |
| ↑8 | Cp. Google Scholar, “Inclusion Guidelines for Webmasters”. Available at: https://scholar.google.com/intl/fr/scholar/inclusion.html [accessed January 5, 2019]. |
| ↑9 | When not Computing Science, the most common heading for those research centres would be Language Technologies, for instance at Carnegie Mellon or Dublin City University, but they are clearly labelled as computational linguistics and deliver MSCs, not MAs. |
| ↑10 | Artificial Intelligence technologies thus contribute to widen the gap between Translation Studies and Computational Linguistics that has been noted by Frank Austermühl, “On Clouds and Crowds – Current Developments in Translation Technology”, T2IN Translation in Transition, 2011, pp. 1-25 and Miguel Jimenez-Crespo, Translation and Web Localization, Abingdon, Routledge, 2013, pp. 88-90. |
| ↑11 | Cp. Unknown Author, “FAANGS v BATS: the world’s tech giants are competing in new markets and the stakes are high”, The Economist, July 7, 2018, pp. 10-11. Cp. also “A wall of money. Quite suddenly the tech firms have become the world’s biggest investors.”, Schumpeter column, The Economist, July 7, 2018, p. 52. |
| ↑12 | Cp. Gisele Sapiro, “Center and periphery: Asymmetrical Flows of Translation”, in Sandra Bermann and Catherine Porter (eds.), A Companion to Translation Studies, Chichester, Blackwell Wiley, 2014, pp. 82-94. |
| ↑13 | Google Translate boasts it can translate over 100 languages, including Portuguese and Arabic but not as efficiently for all language pairs. DeepL focuses to this day on seven Western languages: French, English, German, Italian, Spanish, Dutch, Polish. |
| ↑14 | Within the sample, see Iacer Calixto, Qun Liu and Nick Campbell, “Incorporating Global Visual Features into Attention Based Neural Machine Translation”, Computer Science – Computation and Language, I.2.7, 2017. Available at: https://arxiv.org/pdf/1701.06521.pdf [accessed January 5, 2019] or the work of Elliot et al., funded by French and Dutch public institutions and Amazon Academic Research. Available at: https://arxiv.org/pdf/1710.07177.pdf [accessed January 5, 2019]. For text-to-speech see Wang et al., “Tacotron: Towards End-to-End Speech Synthesis”, Computer Science – Computation and Language, March 29, 2017. Available at: https://arxiv.org/abs/1703.10135 [accessed January 5, 2019]. |
| ↑15 | Cp. Kirti Vashee, “Understanding the economics of machine translation”, Translation Spaces, 2 (1), p. 139. DOI: https://doi.org/10.1075/ts.2.07vas [accessed August 20, 2018]. |
| ↑16 | Florian Faes, “Translate.com exposes highly sensitive information in massive privacy breach”, posted September 7, 2019 on slator. Available at: https://slator.com/technology/translate-com-exposes-highly-sensitive-information-massive-privacy-breach/ [accessed August 20, 2018]. |
| ↑17 | Cp. Google, “Privacy and Terms”. Available at: https://policies.google.com/terms#toc-content [accessed August 20, 2018]. |
| ↑18 | Miguel Jimenez-Crespo, Translation and Web Localization, London and New York, Routledge, 2013, p. 199. |
| ↑19 | Vitali-Rosati, 2018, p. 68. |
| ↑20 | Rory Smith, “The Google Translate World Cup”, New York Times, July 13, 2018. Available at https://www.nytimes.com/2018/07/13/sports/world-cup/google-translate-app.html [accessed August 20, 2018]. |
| ↑21 | A discussion of how machine-produced content is been used and valued by search engines is to be found in Gino Dino, “Google admits its Neural Machine Translation can fool its search algorithm”, posted September 18, 2018 on Slator. Available at https://slator.com/technology/google-admits-neural-machine-translation-can-fool-its-search-algorithm/ [accessed November 4, 2018]. |
| ↑22 | Vitali-Rosati, 2018, p. 83. |
| ↑23 | See for instance the comparative approach of James Meese, Authors, Users and Pirates. Copyright Law and Subjectivity, Harvard, MIT Press, 2018. |
| ↑24 | Cp. Charlotte Hess and Elinor Ostrom (ed.), Understanding Knowledge as a Commons: from Theory to Practice, Harvard, MIT Press, 2007. |
| ↑25 | Cp. Charlotte Hess and Elinor Ostrom, “Ideas, Artifacts, and Facilities: Information as a Common-Pool Resource”, Law and Contemporary Problems, 66 (1/2), 2003. |
| ↑26 | Hess and Ostrom, 2007. |
| ↑27 | Vanessa Enriquez-Raido, “Translators as adaptive experts in a flat world: From Globalization 1.0 to Globalization 4.0?”, IJOC: International Journal of Translation, 10, 2016, pp. 970-988. |

Claire Larsonneur is a Senior Lecturer specializing in Translation Studies, Contemporary British Literature and Digital Humanities at University Paris 8, France. She has co-directed a 4-year international project “The Digital Subject”, funded by the Labex Arts H2H between 2012-2015, and then as a follow-up the June 2016 Cerisy Seminar on the Posthuman. Then she guest-edited Angles #7 on “Digital Subjectivities” (2018). Her next book, co-directed with Dr Renée Desjardins and Dr Philippe Lacour, is Translation in the Digital Age, scheduled for 2020 at Palgrave-Macmillan. (Full CV: http://www.ea-anglais.univ-paris8.fr/spip.php?article1194)